Probabilistic data structures. Quotient filter
In this article, we continue our acquaintance with implementations of probabilistic sets and consider a modern successor of the Bloom filter that is called Quotient filter. Such data structures can effectively work in situations when we need to handle billions of elements and have optimized memory access.
We continue to discover a problem of approximate membership and if you miss the Bloom filter article, you might like to read it first.
One of the main limitations of Bloom filters that we mentioned early was significantly bad performance when your data doesn't pass into main memory (filter is too big). Of course, one can use a disk to store some parts of the filter. But remember, to add or test elements in Bloom filter we need to perform as many random accesses as we have hash function, which is fast enough in the memory, but not on your HDD (on SSD it's a bit faster, but still not so good). So, if you need to be able to store a lot of elements, prepare enough memory ...
But that if we can change the storage algorithm to store all data related to one element really close with the need to have random access only once. Sounds good, the approach is to use only one hash function, but then we need to deal with high collision probability. Quite smart solution is known as Quotient filter.
Quotient filter
Quotient filter was introduced by Michael Bender et al. in 2011. It is a space-efficient probabilistic data structure that implements a probabilistic set with 4 operations:
- add element into the set
- delete element from the set
- test whether an element is a member of the set
- test whether an element is not a member of the set
Quotient filter can be described by 2 parameters:
- `p` - size (in bits) for fingerprints
- 1 hash function that generates such fingerprints
Quotient filter doesn't store the element itself, an only p-bit fingerprint is stored.
Quotient filter is represented as a compact open hash table with `m = 2^q` buckets. The hash table employs quotienting, a technique suggested by D. Knuth:
- the fingerprint `f` is partitioned into:
- the `r` least significant bits (`f_r = f mod 2^r`, the remainder)
- the `q = p - r` most significant bits (`f_q = ⌊\frac{f}{2^r}⌋`, the quotient)
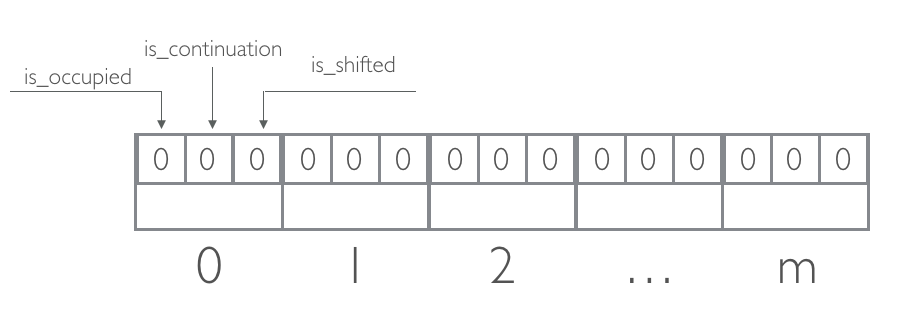
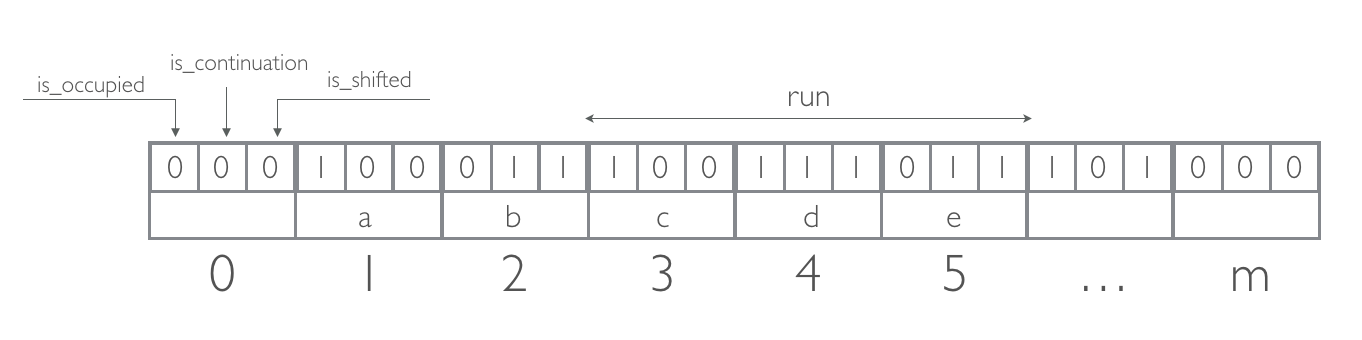
The remainder is stored in a bucket indexed by the quotient. Each bucket contains 3 bits, all 0 at the beginning: is_occupied, is_continuation, is_shifted.
If two fingerprints `f` and `f′` have the same quotient (`f_q = f′_q`) - it is a soft collision. All remainders of fingerprints with the same quotient are stored contiguously in a run.
If necessary, a remainder is shifted forward from its original location and stored in a subsequent bucket, wrapping around at the end of the array.
- is_occupied is set when the bucket `j` is the canonical bucket (`f_q = j`) for some fingerprint `f`, stored (somewhere) in the filter
- is_continuation is set when the bucket is occupied but not by the first remainder in a run
- is_shifted is set when the remainder in the bucket is not in its canonical bucket
Algorithm
To test an element
- Apply the hash function the to element and calculate fingerprint `f`.
- Calculate quotient `f_q` and remainder `f_r` for the fingerprint `f`.
- If bucket `f_q` is not occupied, then the element definitely not in the filter.
- If bucket `f_q` is occupied:
- starting with bucket `f_q`, scan left to locate bucket without set is_shifted bit.
- scan right with running count (is_occupied: +1, is_continuation: -1) until the running count reaches 0 - when it's the quotient's run.
- compare the stored remainder in each bucket in the quotient's run with `f_r`
- if found, than element is (probably) in the filter, else - it is definitely not in the filter.
To add an element
- Apply the hash function the to element and calculate fingerprint `f`.
- Calculate quotient `f_q` and remainder `f_r` for the fingerprint `f`.
- Follow a path similar to test procedure until certain that the fingerprint is definitely not in the filter
- Choose bucket in the current run by keeping the sorted order and insert remainder `f_r` (set is_occupied bit)
- Shift forward all remainders at or after the chosen bucket and update the buckets' bits.
Example
Consider Quotient filter with quotient size `q = 3` and 32-bit signed MurmurHash3 as `h`.
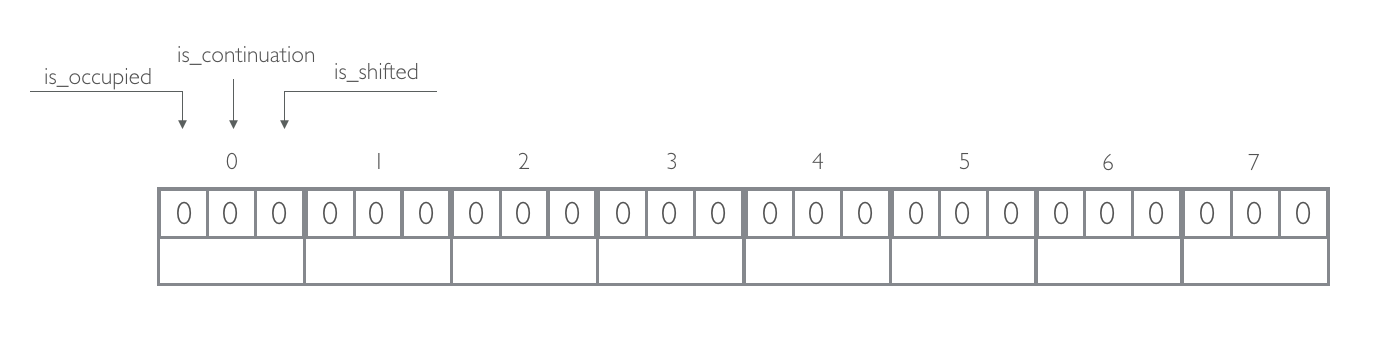
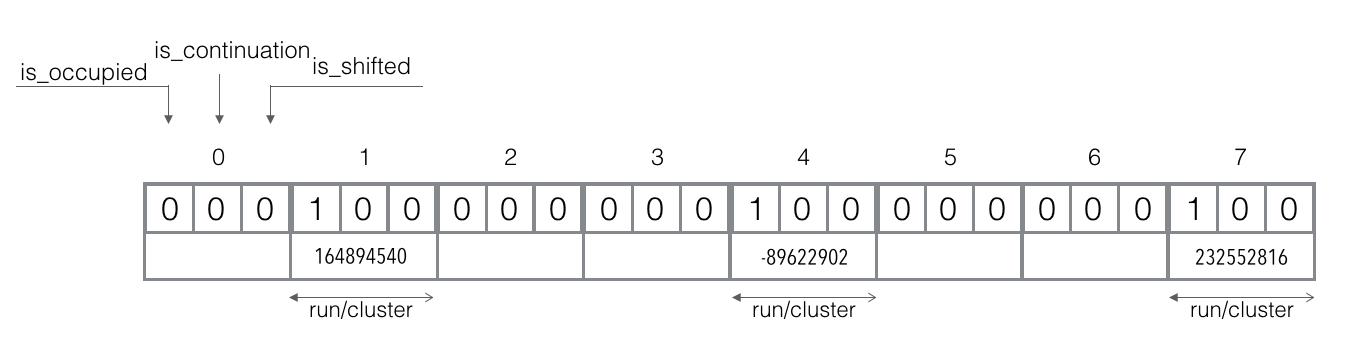
Add elements amsterdam, berlin, london:
- `f_q("amsterdam") = 1`, `f_r("amsterdam") = 164894540`
- `f_q("berlin") = 4`, `f_r("berlin") = -89622902`
- `f_q("london") = 7`, `f_r("london") = 232552816`
Insertion at this stage is easy since all canonical slots are not occupied. We just store our reminder in their canonical slots.
Add element madrid: `f_q("madrid") = 1`, `f_r("madrid") = 249059682`.
The canonical slot 1 is already occupied. The shifted and continuation bits are not set, so we are at the beginning of the cluster which is also the run's start.
The reminder `f_r("madrid")` is strongly bigger than the existing reminder, so it should be shifted right into the next available slot 2 and shifted bit and continuation bit should be set (but not the occupied bit, because it pertain to the slot, not the contained reminder).
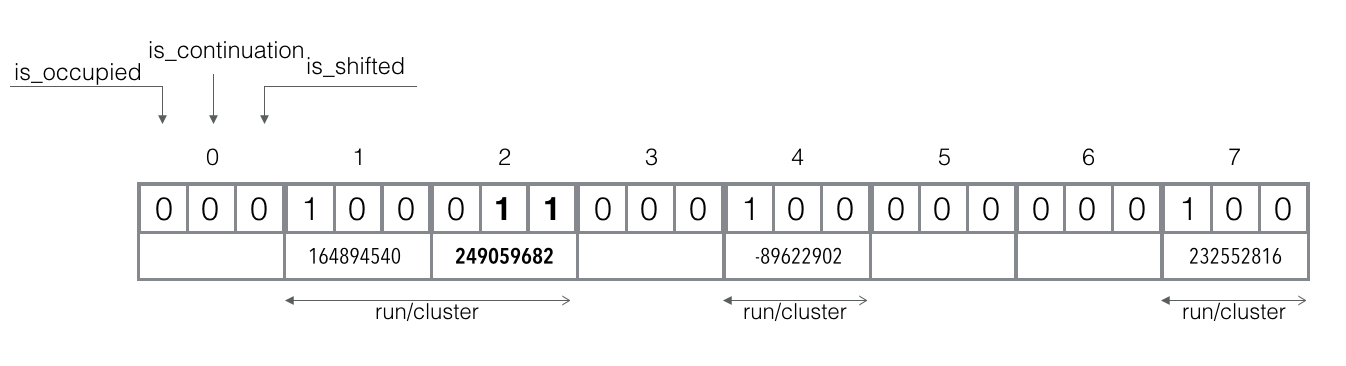
Add element ankara: `f_q("ankara") = 2`, `f_r("ankara") = 62147742`.
The canonical slot 2 is not occupied, but already in use. So, the `f_r("ankara")` should be shifted right into the nearest available slot 3 and its shifted bit should be set. In addition, we need to flag the canonical slot 2 as occupied by setting the occupied bit.
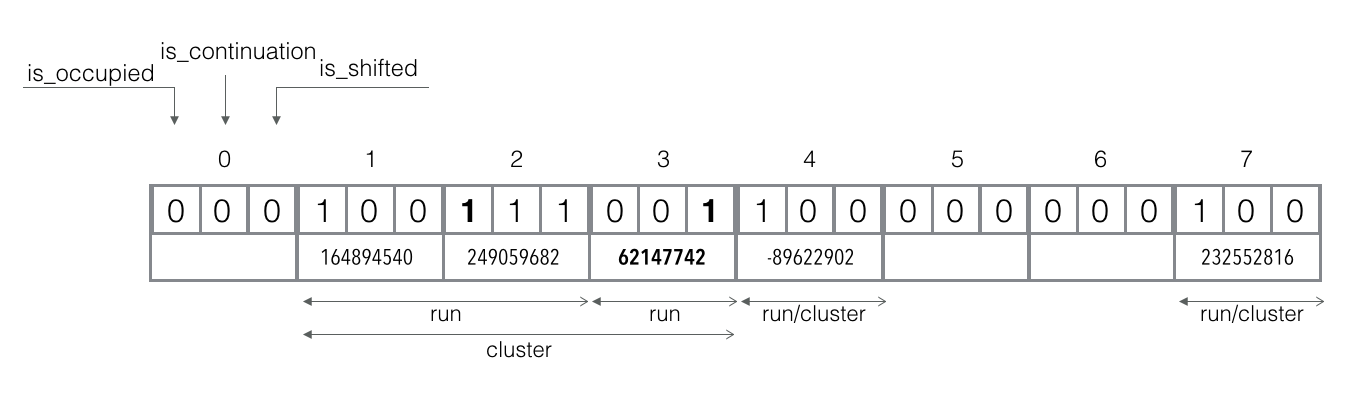
Add element abu dhabi: `f_q("abu dhabi") = 1`, `f_r("abu dhabi") = -265307463`.
The canonical slot 1 is already occupied. The shifted and continuation bits are not set, so we are at the beginning of the cluster which is also the run's start.
The reminder `f_r("abu dhabi")` is strongly smaller than the existing reminder, so all reminders in slot 1 should be shifted right and flagged as continuation and shifted.
If shifting affects reminders from other runs/clusters, we also shift them right and set shifted bits (and mirror the continuation bits if they are set there).
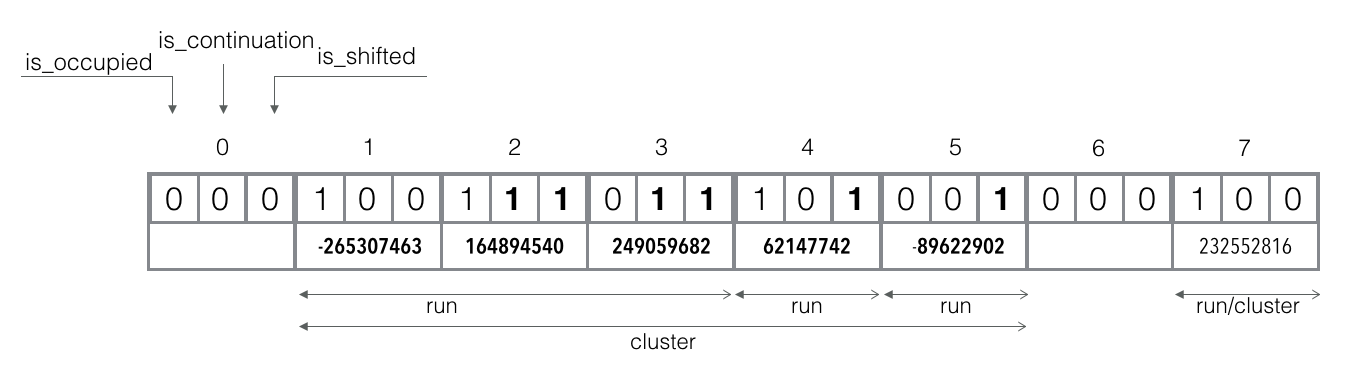
Test element ferret: `f_q("ferret") = 1`, `f_r("ferret") = 122150710`.
The canonical slot 1 is already occupied and it's the start of the run. Iterate through the run and compare `f_r("ferret")` with existing reminders until we found the match, found a reminder that is strongly bigger, or hit the run's end.
We start from slot 1 which reminder is smaller, so we continue to slot 2. Reminder in the slot 2 is already bigger than `f_r("ferret")`, so we conclude that ferret is definitely not in the filter.
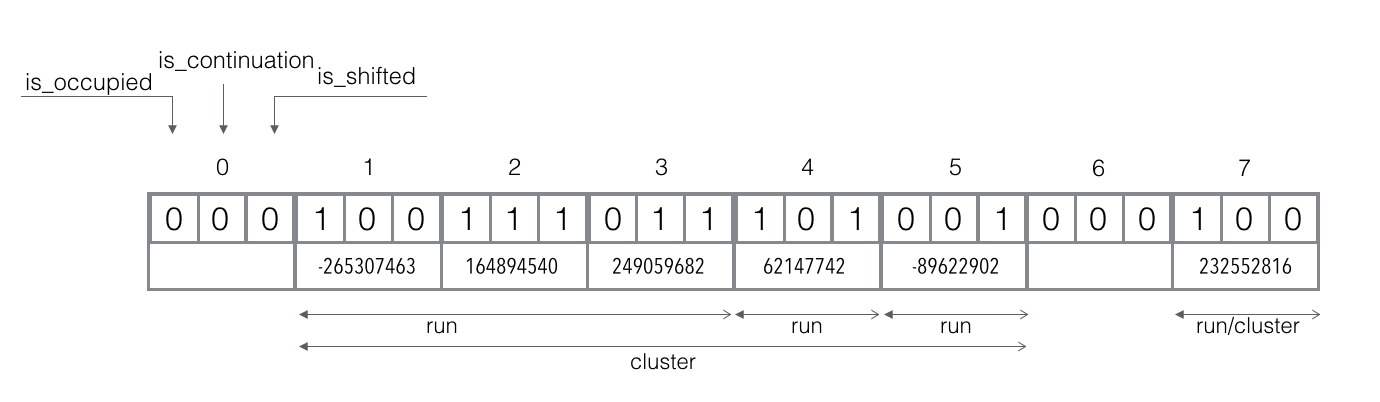
Test element berlin: `f_q("berlin") = 4`, `f_r("berlin") = -89622902`.
The canonical slot 4 is already occupied, but shifted bit is set, so the run for which it is canonical slot exists, but is shifted right.
First, we need to find a run corresponding to the canonical slot 4 in the current cluster., so we scan left and count occupied slots. There are 2 occupied slots found (indices 1 and 2), therefore our run is the 3rd in the cluster and we can scan right until we found it (count slots with not set continuation bit).
Our run starts in the slot 5 and we start comparing `f_r("berlin")` with existing values and found exact match, so we can conclude that berlin is probably in the filter.
Properties
-
False positives are possible. The situations when an element is not a member, but filter
returns like it is a member. Fortunately, it's not too probable situation and we can even
estimate
it's probability:
`P(e \in S| e \notin S) \leq \frac{1}{2^r}`
- It's possible to tune probability of false positives responses. As we can see from the formula above, such probability depends on the size of the fingerprint's reminder.
-
False negatives are not possible. Filter returns that an element isn't a member only if
it's
definitely not a member:
`P(e \notin S| e \in S) = 0`
- Hash function should generate uniformly distributed fingerprints.
- The length of most runs is `O(1)` and it is highly likely that all runs have length `O(log m)`
- Quotient filter efficient for large number of elements (~1B for 64-bit hash function)
Quotient filter vs. Bloom filter
- Quotient filters are about 20% bigger than Bloom filters, but faster because each access requires evaluating only a single hash function.
-
Results of comparison of in-RAM performance (M. Bender et al.):
- inserts. BF: 690 000 inserts per second, QF: 2 400 000 insert per second
- lookups. BF: 1 900 000 lookups per second, QF: 2 000 000 lookups per second
- Lookups in Quotient filters incur a single cache miss, as opposed to at least two in expectation for a Bloom filter.
- Two Quotient Filters can be efficiently merged without affecting their false positive rates. This is not possible with Bloom filters.
- Quotient filters support deletion.
Open-source implementations
- Quotient filter in-memory implementation written in C.
- Quotient filter implementation in pure PHP.
- Quotient filter in-memory implementation in Java.
Read More
- Burton H. Bloom Space/Time Trade-offs in Hash Coding with Allowable Errors. In Communications of the ACM (1970). Vol. 13 (7). Pp. 422-426
- Michael A. Bender et al. Don't Thrash: How to Cache your Hash on Flash. 3rd USENIX Workshop HotStorage'11, June 14-17, 2011
- Michael A. Bender et al. Don't Thrash: How to Cache Your Hash on Flash. In Proceedings of the VLDB Endowment (2012), Vol. 5 (11). Pp. 1627-1637
- Wikipedia page about Quotient filter.
- Sourav Dutta et al. Streaming Quotient Filter: A Near Optimal Approximate Duplicate Detection Approach for Data Streams. In Proceedings of the VLDB Endowment (2013), Vol. 6 (8). Pp. 589-600